
在kali下
github项目
原理简介
文件格式
JPEG文件大体上可以分成两个部分:标记码和压缩数据
标记码:
由两个字节构成,第一个字节是固定值0xFF,后一个字节则根据不同意义有不同数值
在每个标记码之前可以添加数目不限的无意义的0xFF填充,连续的多个0xFF可以被理解为一个0xFF,并表示一个标记码的开始
常见的标记码:
- SOI 0xD8 图像开始
- APP0 0xE0 应用程序保留标记0
- APPn 0xE1 - 0xEF 应用程序保留标记n(n=1~15)
- DQT 0xDB 量化表(Define Quantization Table)
- SOF0 0xC0 帧开始(Start Of Frame)
- DHT 0xC4 定义Huffman表(Define Huffman Table)
- DRI 0XDD 定义差分编码累计复位的间隔(Define Restart Interval)
- SOS 0xDA 扫描开始(Start Of Scan)
- EOI 0xD9 图像结束
压缩数据:
前两个字节保存整个段的长度,包括这两个字节
注:
这个长度的表示方法按照高位在前,低位在后,与PNG文件的长度表示方法不同
例如长度是0x12AB,存储顺序为0x12,0xAB
stegdetect
看用什么工具修改加密过

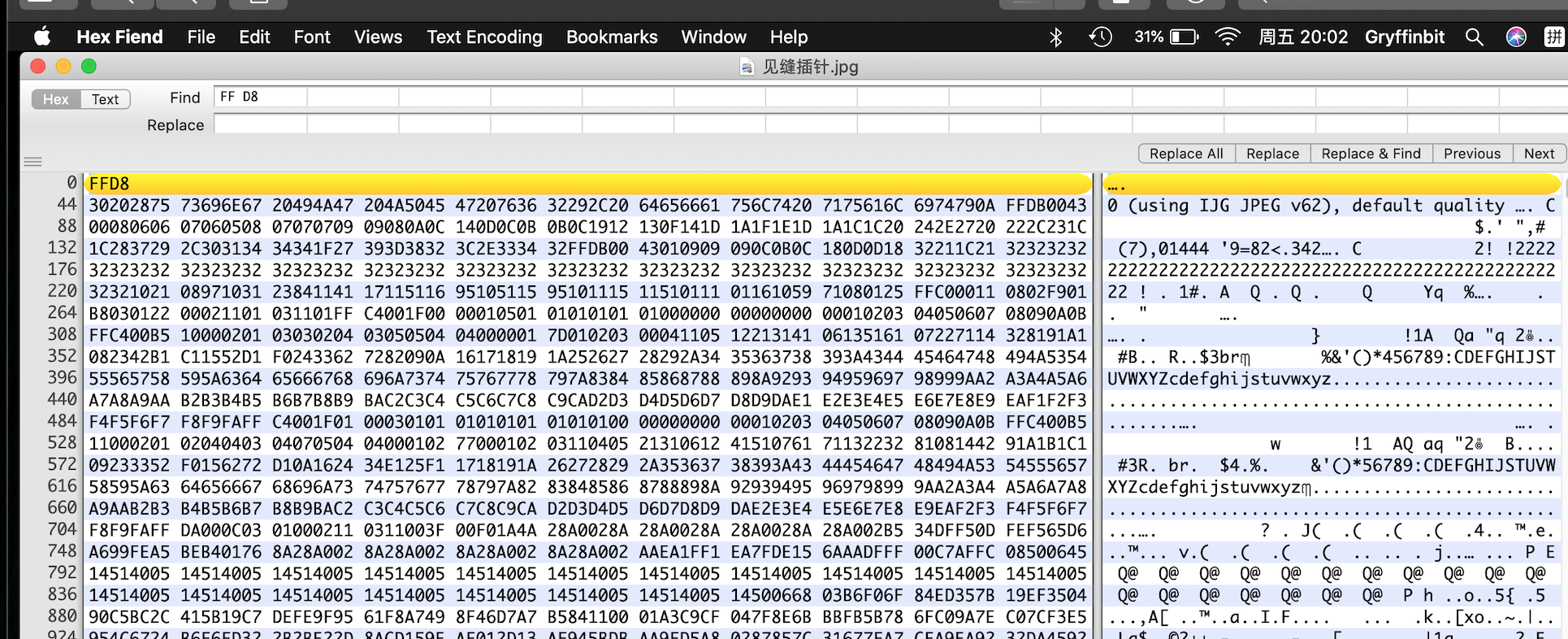
显示有多出的34字节,hex打开后,定位,找到该多余的字节(给出在C0前有34字节无意义填充,可以数出来 C0指的是FFC0)
根据jpeg的格式,在每个标记码之前可以添加数目不限的无意义的0xFF填充, 所以我在FFD8开始~FFC0结束前,隐藏了一段payload。


得到一串十六进制数,当时题目给了提示2 or 3 推出 1. 其实是想给提示,这串数字,实际是十进制数,要把它先转换为十六进制数。最后转换成ascii码

