wireshark网络分析的艺术笔记【工作中的Wireshark】
wireshark抓取包,理想和现实
理想中的TCP传输:客户端每传两个数据包,服务器就立即Ack一下表示已经收到。
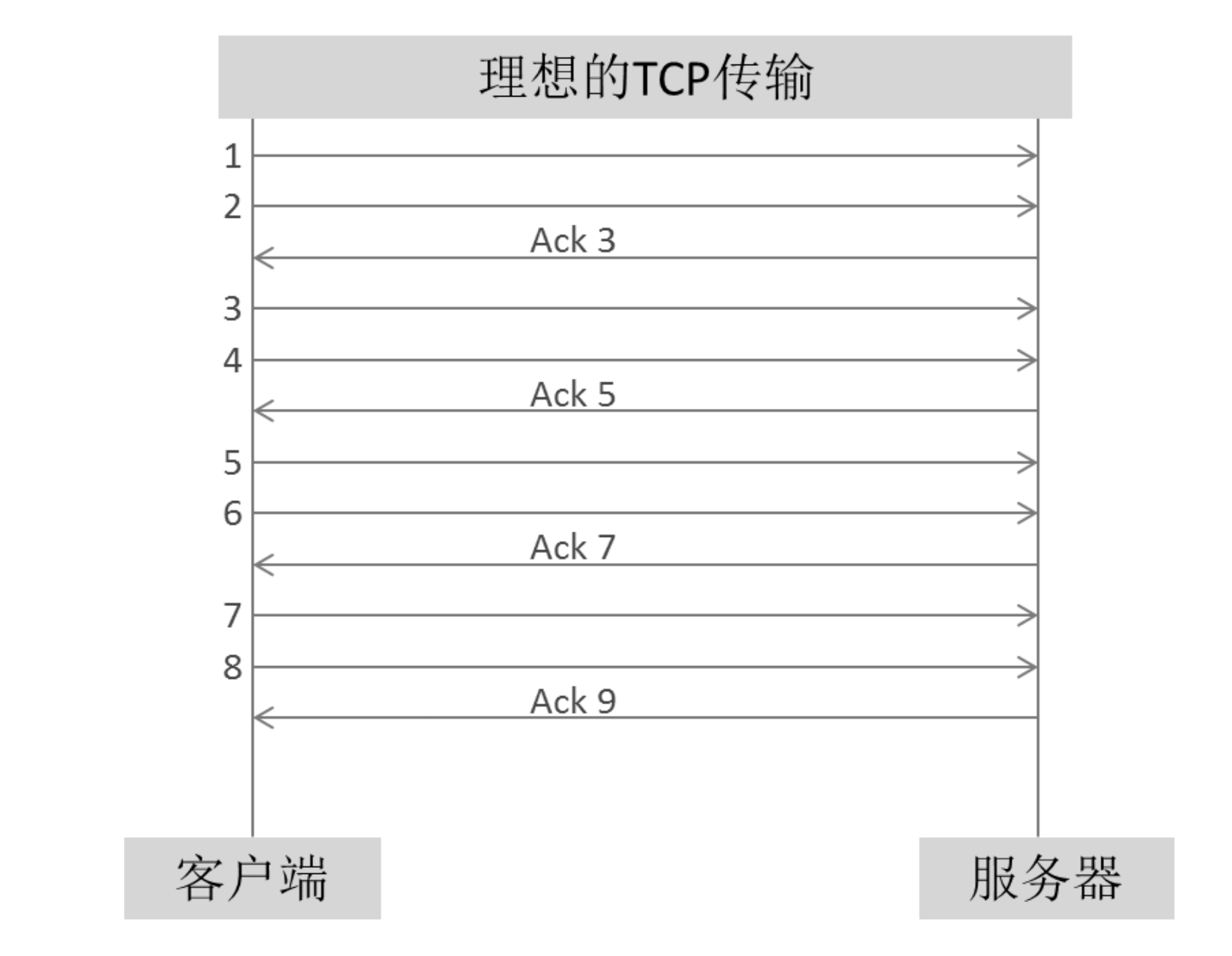
然而这只是从数据接收方的角度所看到的。但实际上网络存在延迟,ack包到达客户端时会之后,可能会存在客户端发完6号包才收到ACK3。
所以抓包时可以尽量两边同时抓包,对照着看。
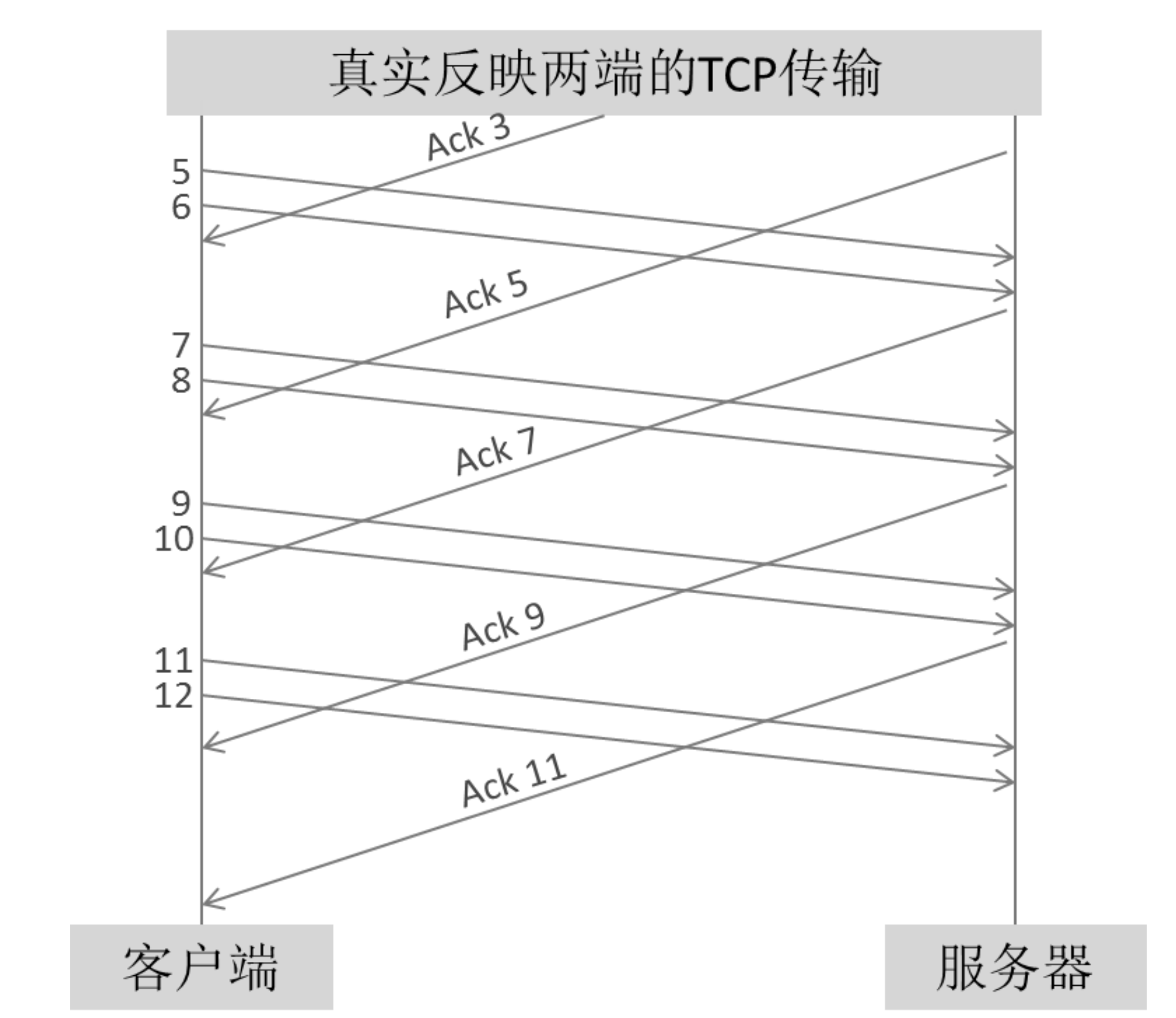
计算“在途字节数”
在途字节数:网络承载量,可以用已经发送出去,但尚未被确认的字节数来表示。在途字节数如果超过网络的承载能力,就会丢包重传
理想情况:网络上只有一个TCP连接在通信,可以通过带宽和延迟来计算最多能承载多少在途字节数。
实际环境:
同一条网络路径是由多台主机之间共享的,根本不知道多少比例的带宽是分配给某个TCP连接。
使用Wireshark分析:
在途字节数=seq+len-ack
seq和len是来自上一个数据发送方的包,ack来自上一个数据接收方的包。【在数据发送方抓到的包,才能用来分析在途字节数】
估算网络拥塞点
网络拥塞点:当发送方一口气向网络中注入大量数据时,就可能超过该网络的承受能力而导致拥塞,这个足以触发拥塞的数据量就称为拥塞点
发生拥塞时的在途字节数即是该时刻的网络拥塞点。估算拥塞点可以简化成:找出拥塞时刻的在途字节数
拥塞的特征是连串丢包,丢包之后就会重传,而 Wireshark 是能够标识出重传包的。
寻找拥塞时刻步骤:先从Wireshark中找到一连串重传包中的第一个,在根据该重传包的seq值找到其原始包,最后计算该原始包发送时刻的在途字节数。
在wireshark上单击analyze菜单,选择expert info选项,找到重传统计表
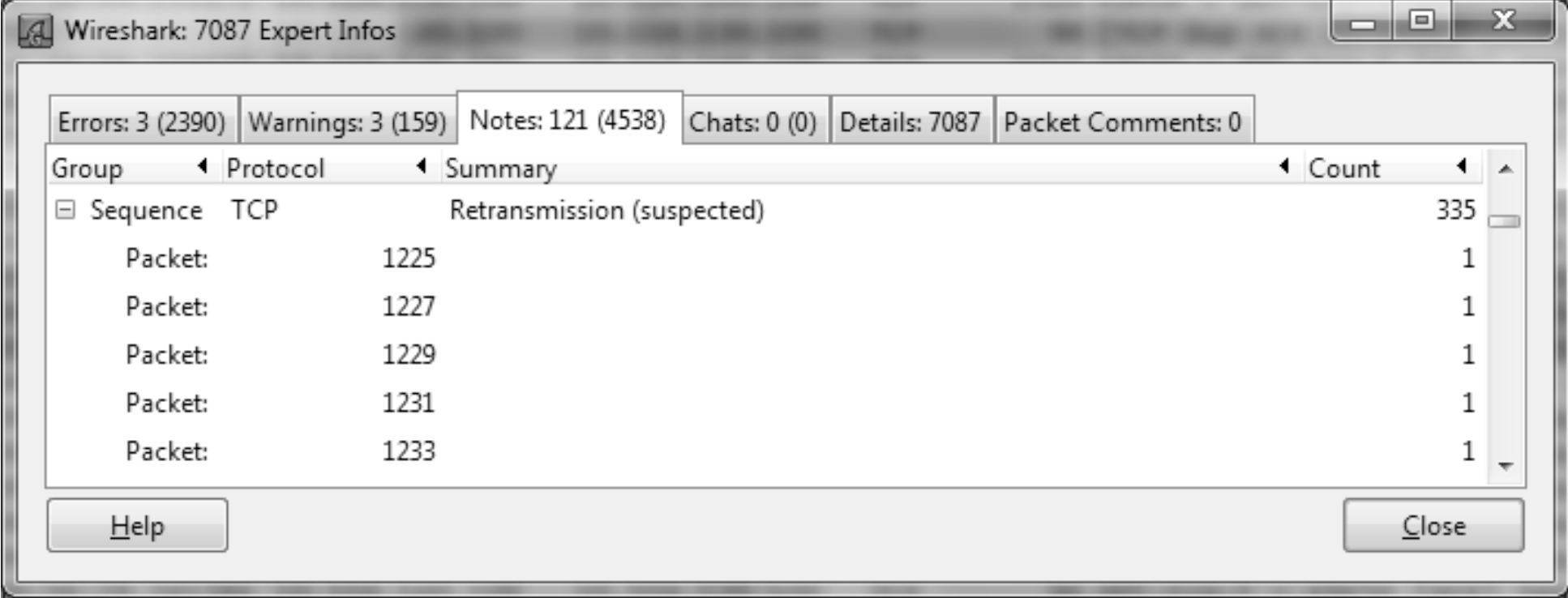
点击第一个重传包No.1225.可见它的seq=1012852.于是用
tcp.seq==1012852作为过滤条件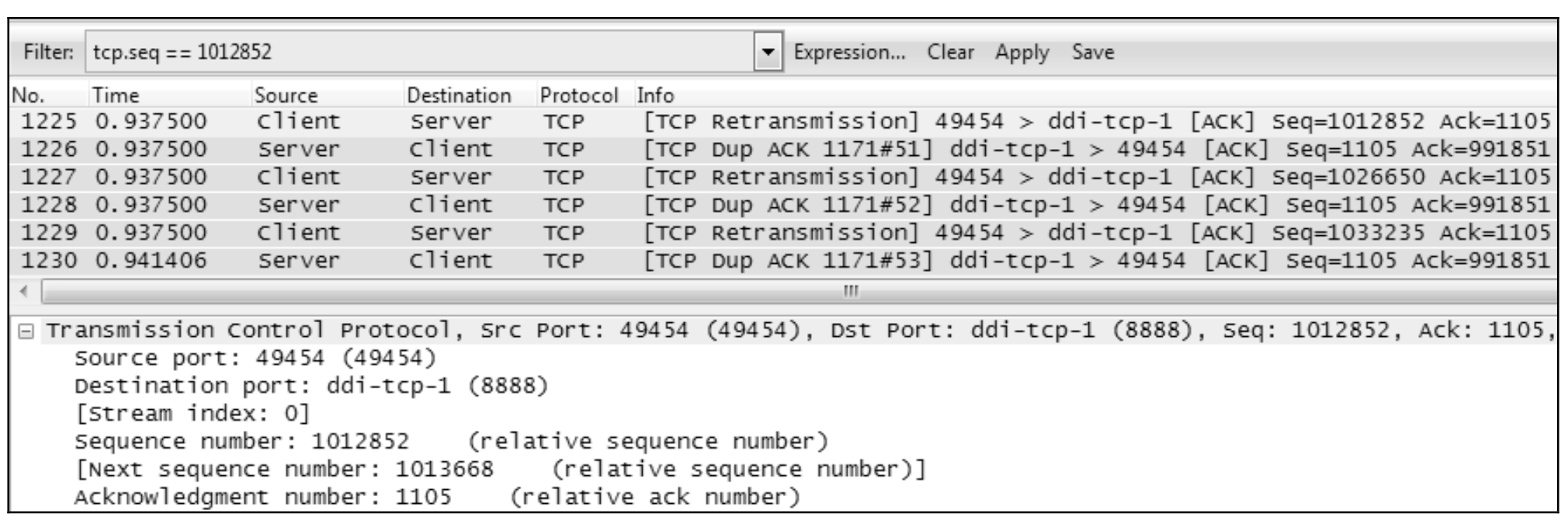
点击apply过滤之后得到了原始包No.1053
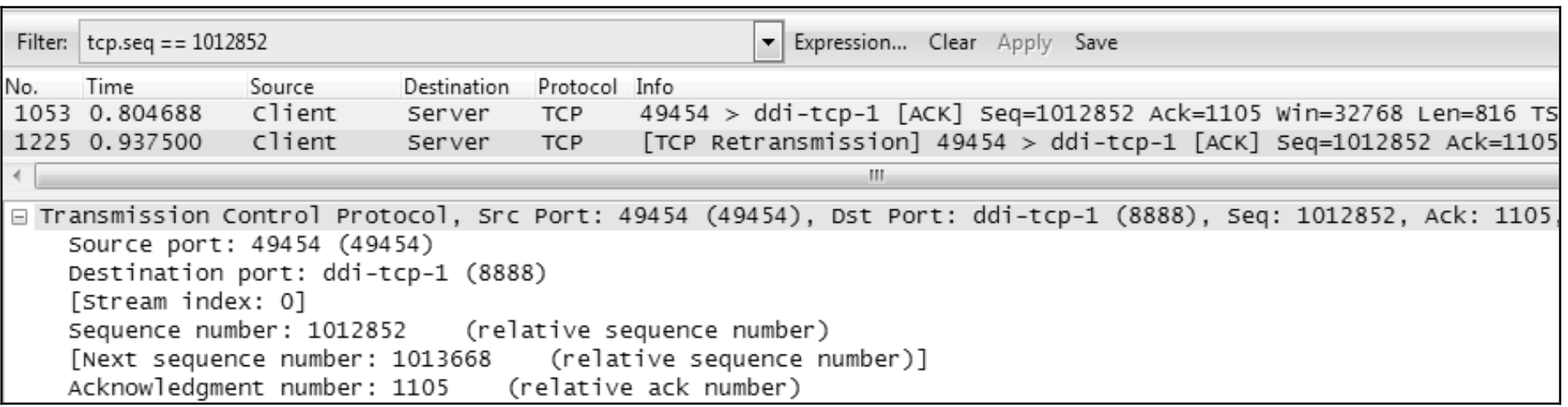
选定1053 号包,然后点击Clear 清除过滤。可见上一个来自服务器端的包是1051 号包。

利用上文计算“在途字节数”的公式,可知当时的在途字节数为1012852(No.1053 的Seq)+816(No.1053 的Len)− 910546(No.1051 Ack)=103122字节。
最好多次采样,然后选定一个合适的值作为该连接的拥塞点(不应该取平均值,而应该取一个偏小的)。
LSO
LSO 是什么呢?它是为了拯救 CPU 而出现的一个创意。随着网络进入千兆和万兆时代,CPU的工作负担明显加重了。625MB/s 的网络流量大约需要耗费5 GHz 的CPU,这已经需要一个双核2.5 GHz CPU的全部处理能力了。为了缓解CPU 的压力,最好把它的一些工作外包(offload)给网卡,比如 TCP 的分段工作。
传统的网络工作方式是这样的:应用层把产生的数据交给 TCP 层,TCP 层再 根据 MSS 大小进行分段(由 CPU 负责),然后再交给网卡。而启用 LSO 之后, TCP 层就可以把大于 MSS 的数据块直接传给网卡,让网卡来负责分段工作了。
比如本例子中的“Seq=348586,Len=2776”,最后会被网卡分成“Seq=348586,Len=1388”和“Seq=349974,Len=1388”两个包。由于在发送方抓包时相当于 站在 CPU 的视角,所以看到的是一个分段前的大包。假如是在接收方抓包,就是 网卡分段后的两个小包了。本文用到的这个例子还是比较小的数据块,我还经常抓到比这个大十倍以上的。
熟读RFC
RFC(Request For Comments)-意即“请求注解”,包含了关于Internet的几乎所有重要的文字资料
Question:丢包不多,RTT 也很稳定,但数据却传不快。怎么回事
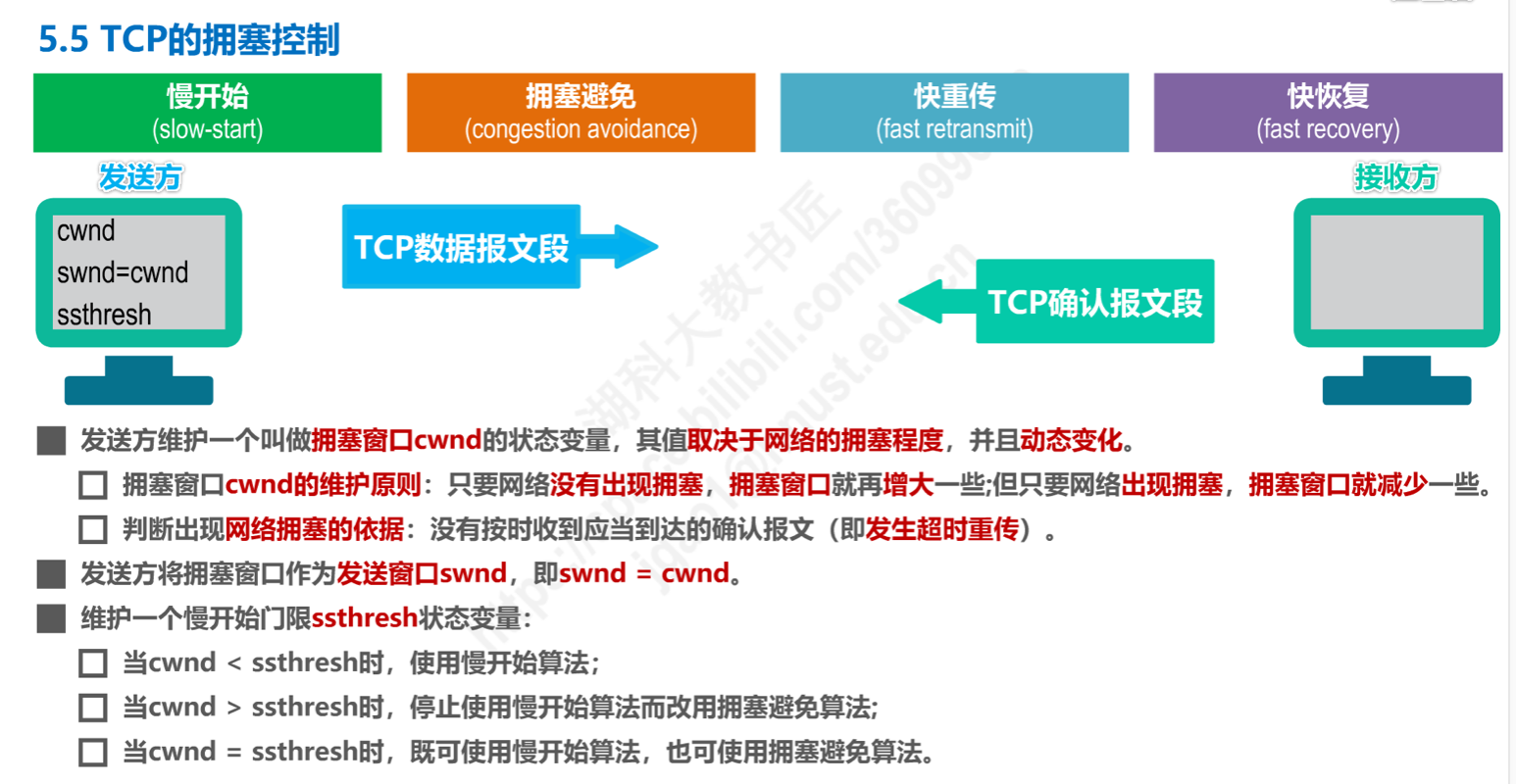
Answer:初步猜测是客户端的 TCP 发送窗口太小。决定客户端发送窗口的因素有两个,分别为网络上的拥塞窗口(Congestion Window,缩写为 cwnd)和服务器上的接收窗口。
cwnd的增长方式
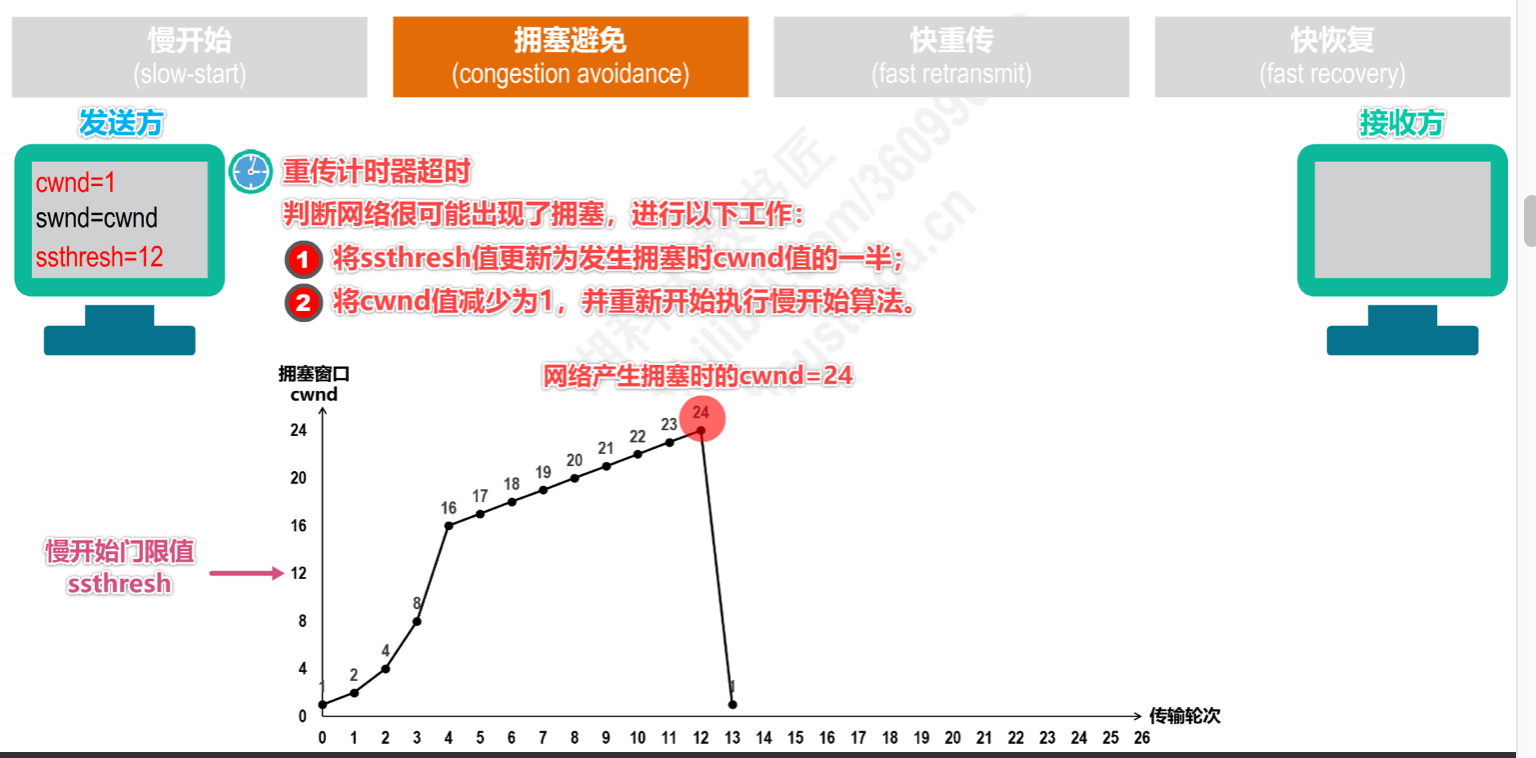
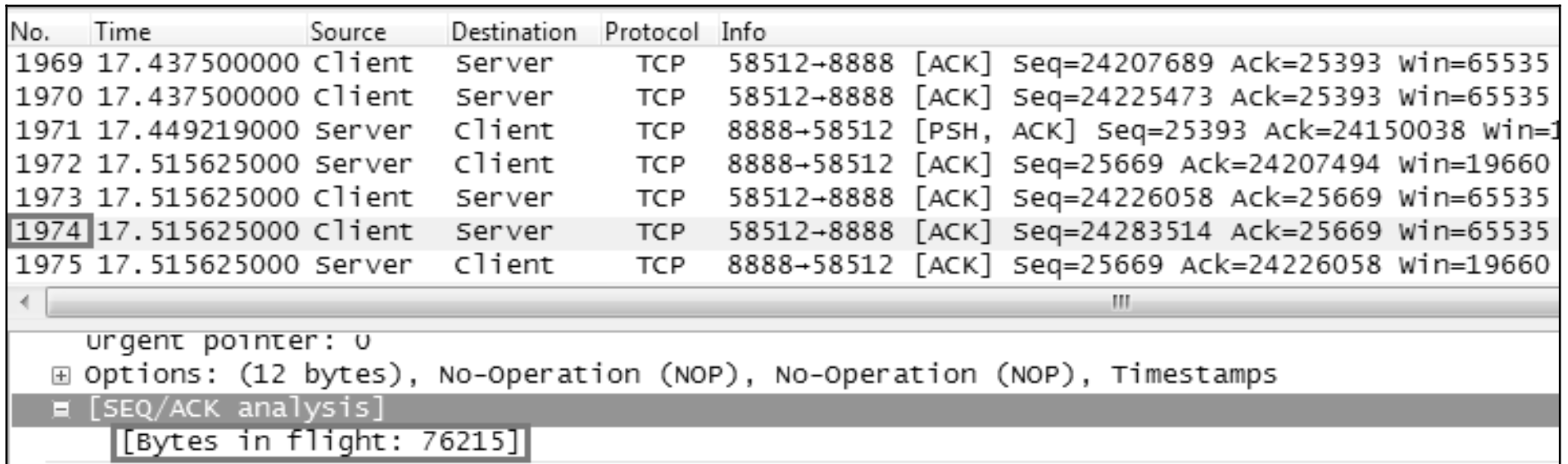
选中一个发送窗口 中最后的那个包,就可以看到它的“Bytes in flight”,它在本案例中就代表了 cwnd 的大小。我随机选中了 1970 号包,从图 4 可见其 cwnd 为 76020。根据图 3 的理 论,如果当时处于“拥塞避免”阶段,那下一个 cwnd 应该就是 76020 加上一个 MSS(以太网中大概为 1460 字节),变成 77480。如果是在慢启动阶段,那就远 远不止这么大。

然而再看下图,Wireshark中却显示下一个RTT(1974号包)的cwnd为76215。 也就是说经历了一个 RTT 之后才增加了 195 个字节,远不如我们所期望的。我接 着又往下看了几个 RTT,还是一样的情况。这意味着客户端的发送窗口增长非常 慢,所以传输效率就很低。
cwnd的一种计算方式:
假如客户端的当前 cwnd 大小为 n 个 MSS,它就会在一个窗口里发出去 n 个包,然后期望收到 n 个 Ack。每收到 1 个 Ack 它就把 cwnd 增加“MSSMSS/cwnd”,于是收到 n 个 Ack 之后就总共增加了“MSS(nMSS/cwnd)”。由于 cwnd 等于 n 个 MSS,所以括号 里的(nMSS/cwnd)大约等于 1,从而实现了每经过 1 个 RTT 就增加 1 个 MSS 的 目的。
所以是cwnd增长过慢导致的,因为只有收到n个ack后才会按照预期的速度增长。但并非所有服务器都是收到n个数据包就回复n个ack的。服务器的网卡上启用了 Large Receive Offload(LRO), 会积累多个 TCP 包再集中处理,因此 Ack 数就比别的服务器少很多,这也解释了为什么其他服务 器没有性能问题。后来系统管理员用 ethtool 命令关闭 LRO 就把问题解决掉了。
错误使用UDP协议传输
UDP时不可靠传输,它缺乏一个机制确保数据安全送达。它不能把大数据块先进行分段,所以很容易被网络层分片,但一个分片的丢失,会导致所有分片都被重传一遍,效率极低。所以在传输大数据的时候,需要使用TCP来进行传输。
关于分片的几个问题
Question1:为什么要分片
Answer1:由于电路交换的双方要独占链路,所以利用率很低,直到后来发明了分组交换的概念,把数据分割成小包后才实现了链路共享。现在的以太网中,以1500字节作为最大传输单位,即MTU=1500。刨去 20 字节的头部,一个 IP 包最多可以携带 1500-20=1480 字节 的数据。当要传输的数据块超过 1480 字节时,网络层就不得不把它分片,封装成多个网络包。
Question2:发送方是怎样确定分片大小的?
Answer2:一般来说,发送方是依据自身的MTU来决定分片大小的。总而言之,目前发送方没有一个很好的机制来确定最佳分片大小,所以实施和运维人员配置MTU时必须谨慎,尽量使网络中每个设备的MTU保持一致
Question3:接收方又是靠什么重组分片的?
Answer 3 :依据off(偏移量)和ID两个值。把ID相同的分片,按照off(偏移量)进行重组。当收到一个包,它包含more fragments = 0的flag,则表示它是最后一个分片,接收方可以开始重组了。
Question 4 :TCP是如何避免被发送方分片的?
Answer 4 :TCP可以避免被发送方分片,是因为它主动把数据分成小段再交给网络层。最大的分段大小称为MSS,它相当于把MTU除去IP头和TCP头之后的大小,所以一个MSS恰好能装进一个MTU中。
UDP则没有MSS的概念,一股脑交给网络层,所以可能被分片。分片和重组都会影响性能,所以UDP在这一点上比TCP落后一些。
Question 5 :TCP是怎样适配接收方的MTU的
Answer 5 : TCP建立连接时必须先进行三次握手,在前两个握手包中双方互相声明了自己的MSS